很喜欢的一个节目做了自己的网站, 有些视频需要开会员或付费观看, 开了会员后看了几集, 虽然比 youtube 上的免费版并没有多加什么内容, 但还是觉得得支持一下原创.
打开浏览器控制台, 发现很多视频都是直接裸奔的, 遂有了写个脚本, 抓下全部视频的想法
工具
BeautifulSoup
用来提取请求到的 HTML 或 XML 文件中的数据
官方文档
requests
用来发起 htps/http 请求
os
辅助工具库, 用来判断记录已下载的视频的文档是否存在
csv
辅助工具库, 用来处理已下载视频记录的数据
pandas
辅助工具库, 用来处理已下载视频记录的数据
思路
获取视频页面链接
进入网站的视频列表页面可以看到有一个 class 为 videoList 的 div, 该标签下存放了当前页面的视频列表.
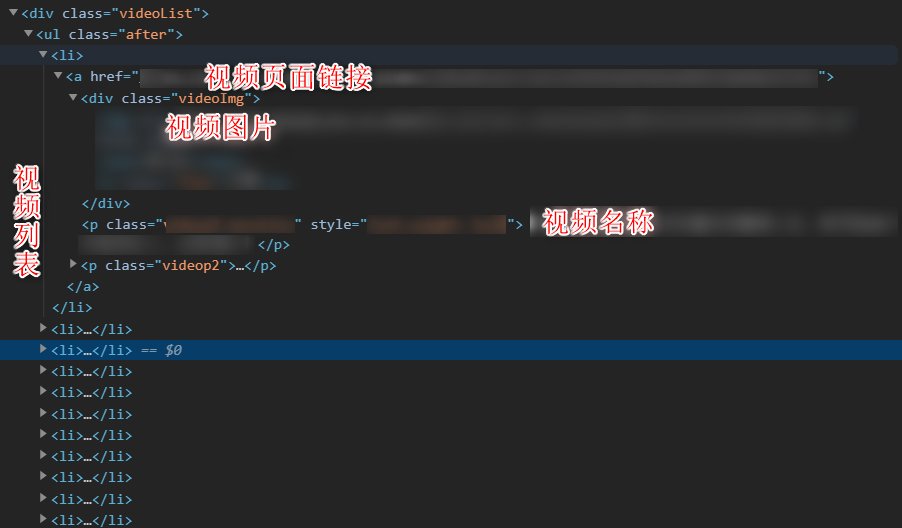
图1. 视频列表页面
通过 request 请求可以获取该页面的内容, 然后理用 BeautifulSoup 处理请求到的 html 页面.
再通过 BeautifulSoup 的方法 .find 找到 class 为 videoList 的 div 标签, 再通过 .find_all 方法找到所有 href 带有 https: 的 a 标签.
这时就获得当前页面所有视频的跳转页面链接和名称了, 遍历这个列表将链接和名称提取出来.
1
2
3
4
5
6
7
8
9
10
11
12
13
| headers={'User-Agent': '你的 user-agent',
'referer':"网站链接",
'origen':'网站链接',
'cookie':'你的 cookie' }
url = '请求页面链接'
start_html = requests.get(url, headers=headers)
soup = BeautifulSoup(start_html.text, features='lxml')
videoList = soup.find('div', class_='videoList').find_all('a', attrs={"href":re.compile(r'^https:')})
for elements in videoList:
vid = elements['href'][51:]
name = elements.find('p', {'class': 'videop1 moreLine'}).text
print(vid, name)
|
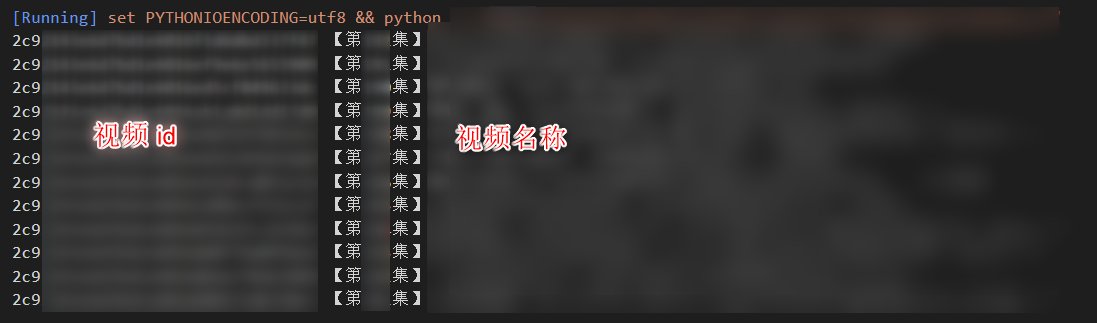
图2. 运行结果
> 其实这时候可以不用 cookie 的, 因为测试发现不登陆的情况下可以正常浏览这个页面
遍历视频列表页面
这时先不急着进入视频页面去下载视频, 可以先看如何遍历所有视频列表页面.
观察到这个页面选择条有一个 onclick 事件, 事件传递参数正式页面数, 而下一页按钮绑定的参数就是下一页页数. 而当没有下一页是, 下一页按钮没有绑定事件.
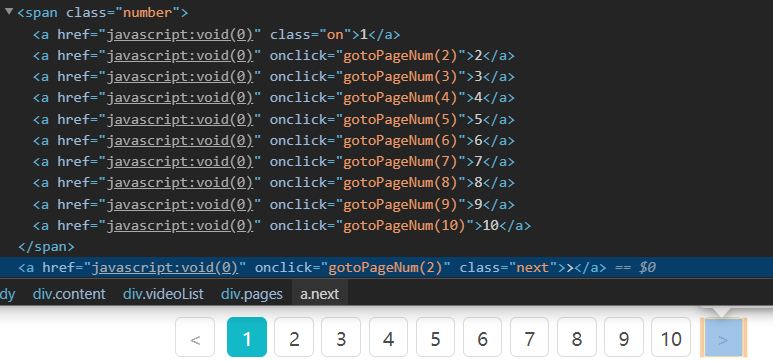

图3, 4. 下一页按钮
通过判断下一页按钮是否含有 onclick 事件可以发现当前页面是否为最后一页.
同时发现每次点击一页, 请求链接上会接上一个参数: &page=x( 页数 ), 于是可以通过该特点来遍历视频列表页面.
因为最开始并不知道到底有多少页, 所以可以直接用 while 1 循环, 再通过判断下一页是否含有 onclick 事件来决定继续或终止循环.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| pageNum = '1'
headers={'User-Agent': '你的 user-agent',
'referer':"网站链接",
'origen':'网站链接',
'cookie':'你的 cookie' }
url = '请求页面链接'
while 1:
start_html = requests.get(url+pageNum, headers=headers)
soup = BeautifulSoup(start_html.text, features='lxml')
videoList = soup.find('div', class_='videoList').find_all('a', attrs={"href":re.compile(r'^https:')})
next_button = soup.find('a', {'class': 'next'})
for elements in videoList:
vid = elements['href'][51:]
name = elements.find('p', {'class': 'videop1 moreLine'}).text
if('onclick' not in str(next_button)):
break
else:
pageNum = next_button['onclick'][12:-1]
|
这里通过直接整数循环也没问题, 只是上面的方法普适性更强
判断视频是否已下载
这里没啥好说的, 代码也很简单, 就两个判断: 1. 记录文件是否存在, vid 是否存在.
1
2
3
4
5
6
7
8
9
10
11
12
| def checkVid(vid, name):
if(os.path.exists('downloaded_video.csv')):
data = csvF.readCSV()
vids = data['video_id'].values.tolist()
if(vid not in vids):
downloadVideo(vid, name)
data.loc[len(data)] = [vid, name]
csvF.writeCSV(data)
else:
downloadVideo(vid, name)
data = [{'video_id': vid, 'video_name': name}]
csvF.newCSV(data)
|
进入视频页面并下载视频
用浏览器进入视频页面可以观察到视频链接就在一个 video 标签中, 所以进入该页面后, 找到该标签再从该标签获取链接就可以了.

进入视频页面与 2.1 过程一致, 但要注意, 这个时候就需要 cookie 了.
但实际发现通过 python 进入获取到的页面并没有包含后面的 src 这个链接.
1
| <video width="100%" height="100%" id="video1" poster="http://图片链接.jpg"></video>
|
再看一下页面请求过程中有一个请求, 返回的正是带有视频链接的 video 标签

于是而且发现该请求用的正是 2.1 获取到的 vid, 所以猜测可以直接通过这个请求来获取视频链接而不用进入视频页面. 后面的测试也证实了这个猜测:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| def downloadVideo(vid, name):
headers = {'GET': '请求链接',
'Host': '网站地址',
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
'Upgrade-Insecure-Requests': '1',
'DNT': '1',
'User-Agent': '你的 user-agent',
'Sec-Fetch-User': '?1',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'navigate',
'Referer': '网站地址',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en-GB;q=0.8,en;q=0.7,zh-TW;q=0.6,da;q=0.5,ja;q=0.4',
'Cookie': '你的 cookie',
}
videoPage_html = requests.get('请求链接', headers=headers)
soup = BeautifulSoup(videoPage_html.text, features='lxml')
url = soup.find('source')['src'][2:-2]
r = requests.get(url)
with open(name+'.mp4', "wb") as code:
code.write(r.content)
|
至此完成整个抓包过程.
python 真的方便好用, 3, 40 行有效代码就能做一个爬虫.
完整代码
主代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| from bs4 import BeautifulSoup
import csvFunction as csvF
import requests
import re
import os
import csv
import pandas as pd
def downloadVideo(vid, name):
headers = {'GET': '请求链接',
'Host': '网站地址',
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
'Upgrade-Insecure-Requests': '1',
'DNT': '1',
'User-Agent': '你的 user-agent',
'Sec-Fetch-User': '?1',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'navigate',
'Referer': '网站地址',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en-GB;q=0.8,en;q=0.7,zh-TW;q=0.6,da;q=0.5,ja;q=0.4',
'Cookie': '你的 cookie',
}
videoPage_html = requests.get('请求链接', headers=headers)
soup = BeautifulSoup(videoPage_html.text, features='lxml')
url = soup.find('source')['src'][2:-2]
r = requests.get(url)
with open(name+'.mp4', "wb") as code:
code.write(r.content)
def checkVid(vid, name):
if(os.path.exists('downloaded_video.csv')):
data = csvF.readCSV()
vids = data['video_id'].values.tolist()
if(vid not in vids):
downloadVideo(vid, name)
data.loc[len(data)] = [vid, name]
csvF.writeCSV(data)
else:
downloadVideo(vid, name)
data = [{'video_id': vid, 'video_name': name}]
csvF.newCSV(data)
pageNum = '1'
headers={'User-Agent': '你的 user-agent',
'referer':"网站链接",
'origen':'网站链接',
'cookie':'你的 cookie' }
url = '请求链接'
while 1:
start_html = requests.get(url+pageNum, headers=headers)
soup = BeautifulSoup(start_html.text, features='lxml')
next_button = soup.find('a', {'class': 'next'})
videoList = soup.find('div', class_='videoList').find_all('a', attrs={"href":re.compile(r'^https:')})
for elements in videoList:
vid = elements['href'][51:]
name = elements.find('p', {'class': 'videop1 moreLine'}).text
checkVid(vid, name)
if('onclick' not in str(next_button)):
break
else:
pageNum = next_button['onclick'][12:-1]
|
csv 处理库 csvFunction
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| import pandas as pd
encode = 'utf-8'
path = '你的路径/downloaded_video.csv'
def newCSV(data):
df = pd.DataFrame(data, columns=['video_id', 'video_name'])
df.to_csv(path, index=False, encoding='utf_8_sig')
def readCSV():
data = pd.read_csv(path, encoding=encode)
return data
def sortData(data, columnName):
return data.sort_values(columnName)
def writeCSV(data):
data.to_csv(path, index=False,encoding='utf_8_sig')
|